Moravec’s paradox: “The deliberate process we call reasoning is, I believe, the thinnest veneer of human thought, effective only because it is supported by this much older and much more powerful, though usually unconscious, sensorimotor knowledge.” [Mind Children, 1988 – Hans Moravec]. “Demonstrating real intelligence requires to have a body and to interact with an environment, taking inspiration from the natural evolution of complex behaviours in animal species”. Reproducing child-level sensorimotor abilities, like locomotion or object manipulation, is more intricate than learning to play abstract games like go or poker.
Developmental robotics: “Developmental robotics is a scientific field which aims at studying the developmental mechanisms, architectures, and constraints that allow lifelong and open-ended learning of new skills and new knowledge in embodied machines. As in human children, learning is expected to be cumulative and of progressively increasing complexity, and to result from self-exploration of the world in combination with social interaction. The typical methodological approach consists in starting from theories of human and animal development elaborated in fields such as developmental psychology, neuroscience, developmental and evolutionary biology, and linguistics, then to formalise and implement them in robots, sometimes exploring extensions or variants of them. The experimentation of those models in robots allows researchers to confront them with reality, and as a consequence developmental robotics also provides feedback and novel hypothesis on theories of human and animal development.”[Developmental Robotics, 2012 – Pierre-Yves Oudeyer]
Learning Progressions: Learning progressions in science are empirically-grounded and testable hypotheses about how students’ understanding of, and ability to use, core scientific concepts and explanations and related scientific practices grow and become more sophisticated over time, with appropriate instruction [Learning Progressions: New Tools for Improvement, 2009]
Situated and Embodied Cognition: “Cognition is embodied when it is deeply dependent upon features of the physical body of an agent, that is, when aspects of the agent’s body beyond the brain play a significant causal or physically constitutive role in cognitive processing” [Embodied Cognition , 2011] – “Situated cognition is a theory which emphasises that people’s knowledge is constructed within and linked to the activity, context, and culture in which it was learned” [Situated Cognition (Brown, Collins, & Duguid), 2017]
Reward Shaping: reward shaping is a method for engineering a reward function in order to provide more frequent feedback on appropriate behaviours. It is most often discussed in the reinforcement learning framework [Reward Shaping, Eric Wiewiora].
Joint Attention: Joint attention is the shared gaze behaviour of two or more individuals on an object or an area of interest and has a wide range of applications such as human-computer interaction, educational assessment, treatment of patients with attention disorders, and many more. [Attention Flow: End-to-End Joint Attention Estimation, Sümer, 2020]
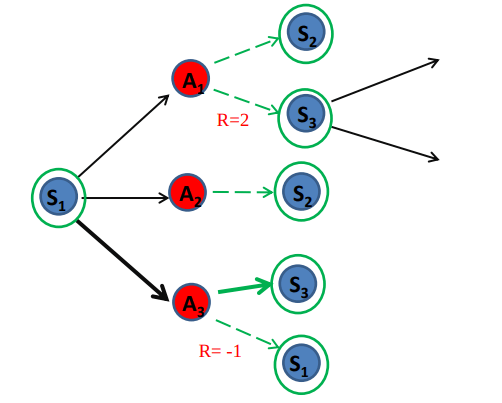
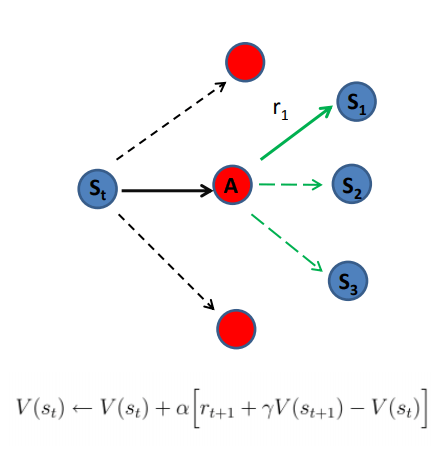
Model-free reinforcement learning and Model-based reinforcement learning [Model-free Methods, MIT 2014]. In model-based we update the value function Vπ(S) using all possible s’. In model-free we take a step, and update based on this sample. Model based learning attempts to model the environment, and then based on that model, choose the most appropriate policy. Model–free learning attempts to learn the optimal policy in one step (e.g., Q-learning ).
Nash Equilibrium: “Nash equilibrium is a fundamental concept in the theory of games and the most widely used method of predicting the outcome of a strategic interaction in the social sciences. A game (in strategic or normal form) consists of the following three elements: a set of players, a set of actions (or pure-strategies) available to each player, and a payoff (or utility) function for each player. The payoff functions represent each player’s preferences over action profiles, where an action profile is simply a list of actions, one for each player. A pure-strategy Nash equilibrium is an action profile with the property that no single player can obtain a higher payoff by deviating unilaterally from this profile.” [Nash Equilibrium, Columbia University]
Policy Gradient Methods: Policy gradient methods are a type of reinforcement learning techniques that rely upon optimizing parametrized policies with respect to the expected return (long-term cumulative reward) by gradient descent [Policy Gradient Methods, Scholarpedia]. Policy gradient methods update an agent’s policy, parameterised by
REINFORCE: Also known as Monte Carlo Policy Gradients