Reinforcement learning boasts a substantial history predating the recent surge in deep learning. Reinforcement learning is learning what to do—how to map situations to actions— e.g., acquire a policy, so as to maximize a numerical reward signal (Sutton & Barto, 2000). While this policy could use deep learning, it is not a strict requirement.
Whilst it is certainly beneficial to delve into and advance knowledge of state-of-the-art deep reinforcement learning algorithms, there are advantages to approaching the field from its foundational origins. Let me tell you more about the pros of focusing on both reinforcement learning of the origin and the so-called modern reinforcement learning.
Reinforcement Learning of the origin
Simple and Transparent. First and foremost, by studying the fundamental principles of reinforcement learning, free from the complexities of deep learning, one gains a clearer grasp of core concepts, algorithms, and mechanisms involved in the learning process. This understanding provides valuable insights for designing and tailoring solutions to address specific problems. Classic reinforcement learning algorithms are known for their simplicity and transparency when compared to deep learning models. However, this does not make them uninteresting from a research point of view. The proof of convergence of some of the most common RL algorithms were provided years later their first appearance (Watkins & Dayan 1992, Singh et al. 2000). Moreover, challenges remain in explaining to humans the sequentiality, and interdependence between states, and the rationale behind certain actions for long-term gains. These challenges have sparked significant interest among researchers in the area of explainability in Reinforcement Learning.
Less Computationally Expensive. Secondly, foundational reinforcement learning techniques demonstrate their effectiveness in simple environments, while rendering complex deep learning models is unnecessary and computationally expensive for such cases. The reduced computational requirements of traditional reinforcement learning algorithms make them more accessible and efficient for certain applications.
Transferable to Other Domains. Lastly, the knowledge acquired from studying foundational reinforcement learning can be readily transferred to other related fields and domains, such as cognitive science, robotics, control systems, and decision-making processes, enhancing its practical versatility.
Modern Reinforcement Learning
Suitable for Complex Tasks. On the other hand, deep reinforcement learning leverages deep neural networks to automatically learn feature representations from raw data, eliminating the need for manual feature engineering, i.e., end-to-end learning. This enables the algorithm to extract complex and abstract features from the environment, making it more capable of handling high-dimensional and unstructured inputs. Thus, deep reinforcement learning can efficiently handle continuous action spaces and high-dimensional state spaces, making it suitable for tasks with a large number of possible actions and allowing the agent to perceive and analyze complex environments.
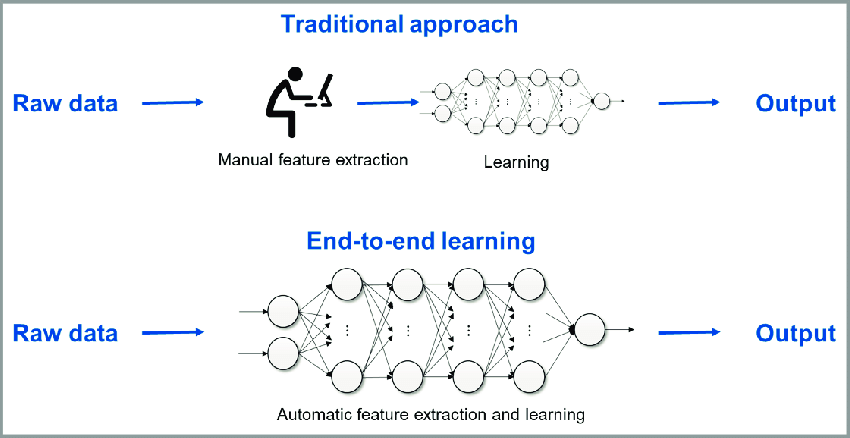
Higher-performing. Moreover, deep reinforcement learning can handle complex decision-making tasks by learning intricate and hierarchical policies. This allows the agent to make more sophisticated decisions, leading to improved performance in complex environments. In contrast, the blog post of Alex Irpan, “Deep Reinforcement Learning Doesn’t Work Yet”, well highlights how deep RL can be horribly sample inefficient.
Popular and with plenty of dedicated libraries. Both Tensorflow and Pytorch now include a set of well-tested modular components to design, implement, and test RL algorithms. Other interesting libraries, such as Sequential Learning of Agents (SaLinA), RL Reach, and BlackBoard Reinforcement Learning (BBRL) also offer lightweight implementations for reinforcement learning.
Overall, studying reinforcement learning independently from deep learning lays a strong foundation for exploring and exploiting the potential of both traditional and cutting-edge techniques in various real-world applications. Deep reinforcement learning, being a fusion of reinforcement learning and deep learning, holds tremendous promise in solving complex and high-dimensional problems, making it a compelling avenue for further exploration and research. By building a solid understanding of both classic and deep reinforcement learning, one can effectively harness the strengths of each approach. The key message is that while it’s marvelous to work on complex simulations with thousands of epochs and develop agents capable of defeating the world champion of Go, it is essential to remember that sometimes, simplicity is the ultimate sophistication, as someone said.
- Keep in mind that beyond learning a policy from direct interaction with the environment, it is possible to learn a reward function from a set of demonstrations provided by another expert agent, a human most of the time. In this context, Inverse Reinforcement Learning approaches (IRL) have been proven to be extremely useful in many critical domains (e.g., socially adaptive navigation, energy efficient driving).
- Instead of merely memorizing chunks of code and the grammar of a new library, try to grasp the underlying functioning of the algorithms you are using.
- While ensuring the reliability and reproducibility of experiments is essential, it’s worth recognizing that deep learning is just one of the many approaches available to us. Embracing its place alongside other techniques enables a more well-rounded and adaptive approach to problem-solving in the realm of AI.
Not long ago, I took part in a Reinforcement Learning course primarily centered around Deep Reinforcement Learning. My decision to participate in this course stemmed from the desire to update my knowledge about state-of-the-art algorithms and learn more about common baselines to evaluate the effectiveness of the algorithms I was proposing. Despite having assisted and prepared deep learning tutorials and practicals, I realized that I hadn’t fully immersed myself in the subject compared to some of my colleagues, leading me to seek further expertise through this course.
When I embarked on my PhD journey, I was encouraged to take a step back from the deep learning arena. I had an interdisciplinary background in Computer Science and Cognitive Science, and I was lacking formal experience in artificial intelligence. Beginning with the fundamentals of classic artificial intelligence algorithms was a wise decision. This approach allowed me to brush up on search-based algorithms and imitation learning methods and test them in real-world scenarios, including interactions with real people using the system.
While one of my supervisors was introducing me to inverse reinforcement learning and how to formulate my research problem around finding the weights of a linear combination of features it appeared that the rest of the world was primarily occupied with running heavy simulations and fine-tuning hyperparameters for their deep learning models. This disparity in research directions appeared to widen the gap between my approach and the prevailing trends in the field.
As I progressed in my research, I began to question the direction I had taken and the practicality of my work. Subsequently, during job interviews, I had to explain why I held a PhD in artificial intelligence and robotics despite not being specialized in deep learning. This forced me to discover the merits of my approach and demonstrate how it held relevance and value within the field.
I soon came to realize that many working in the domain often ignore the possibility of pushing the boundaries of our knowledge in artificial intelligence without including tf.keras.models.Sequential() in their code. The wide availability of libraries for running deep learning algorithms, while convenient, can be a double-edged sword. It allows many people to execute code without a comprehensive understanding, giving them the impression of working on cutting-edge research but ultimately hindering them from making significant strides forward in the field.
